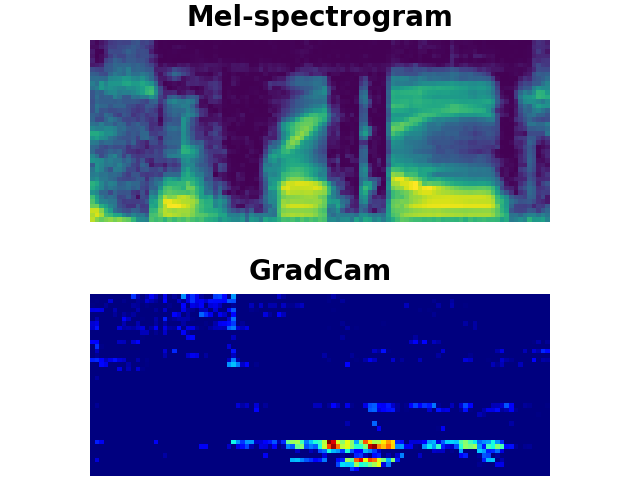
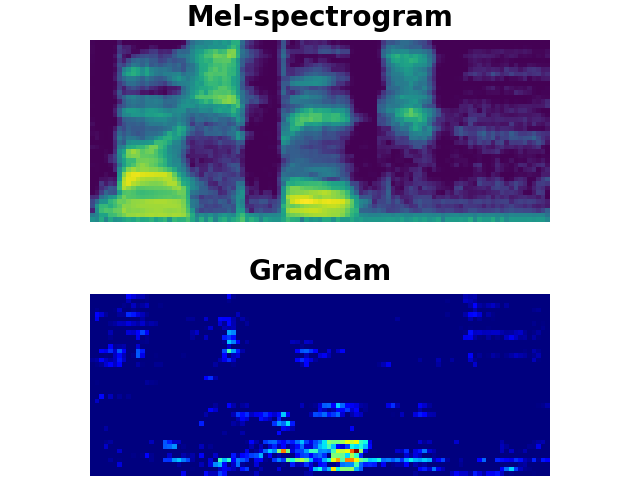
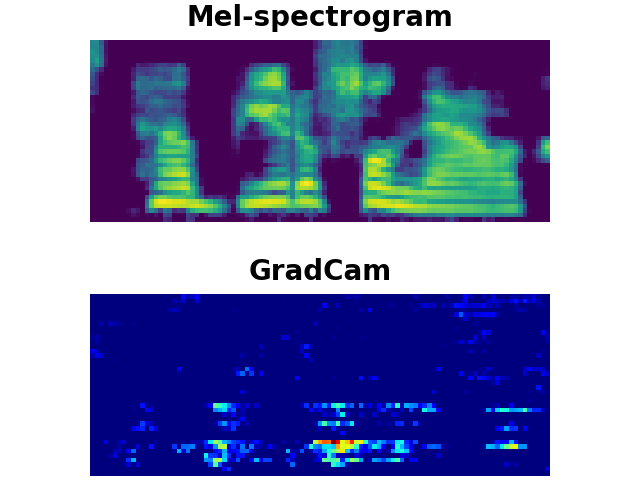
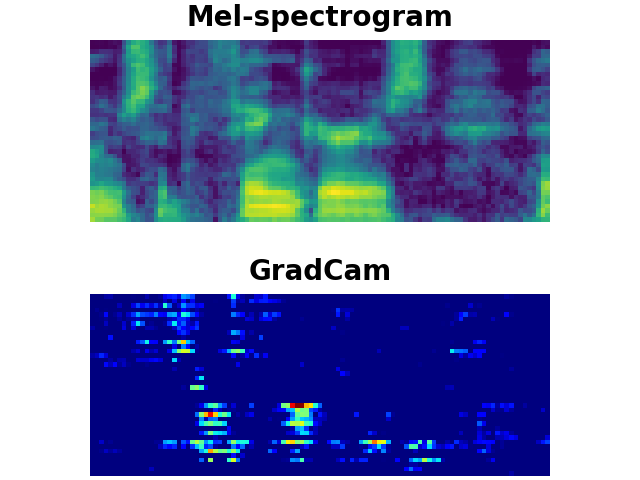
CAT
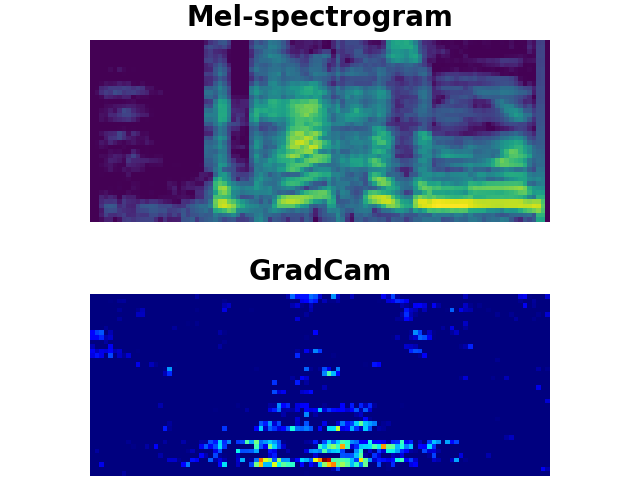
The goal of this work is to detect new spoken terms defined by users. While most previous works address Keyword Spotting (KWS) as a closed-set classification problem, this limits their transferability to unseen terms. The ability to define custom keywords has advantages in terms of user experience.
In this paper, we propose a metric learning-based training strategy for user-defined keyword spotting. In particular, we make the following contributions: (1) We construct a large-scale keyword dataset with an existing speech corpus and propose a filtering method to remove data which degrade a performance of a KWS model. (2) With comprehensive experiments, we prove that metric learning-based pre-training on our dataset, followed by fine-tuning on a smaller in-domain keyword dataset, enriches the KWS model’s representation. (3) For the fair comparison in the KWS field, we propose an unified evaluation protocol and metrics.
Our proposed system does not require incremental training on the user-defined keywords, and outperforms previous works by a significant margin on the Google Speech Commands dataset using the proposed as well as the existing metricsminimal additional training images.