
The goal of this work is background-robust continuous sign language recognition. Most existing Continuous Sign Language Recognition (CSLR) benchmarks have fixed backgrounds and are filmed in studios with a static monochromatic background. However, signing is not limited only to studios in the real world.
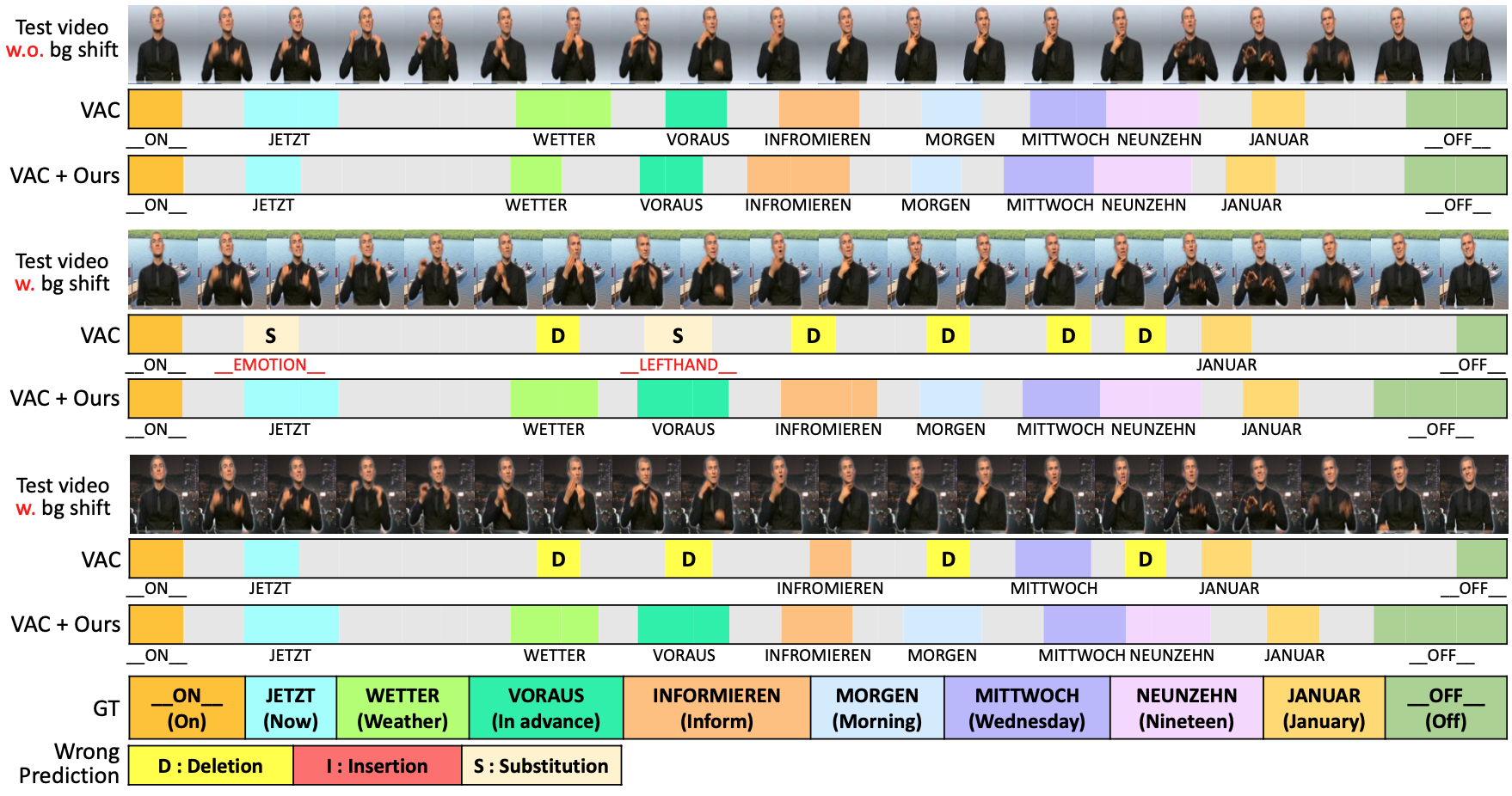
In order to analyze the robustness of CSLR models under background shifts, we first evaluate existing state-of-the-art CSLR models on diverse backgrounds. To synthesize the sign videos with a variety of backgrounds, we propose a pipeline to automatically generate a benchmark dataset utilizing existing CSLR benchmarks. Our newly constructed benchmark dataset consists of diverse scenes to simulate a real-world environment. We observe that even the most recent CSLR method cannot recognize glosses well on our new dataset with changed backgrounds.
In this regard, we also propose a simple yet effective training scheme including (1) background randomization and (2) feature disentanglement for CSLR models. The experimental results on our dataset demonstrate that our method generalizes well to other unseen background data with minimal additional training images.
Most publicly available CSLR benchmarks are curated from either studio or TV broadcasts, where background images are fixed and monochromatic. A naïve solution to this would be constructing a new dataset outside the studio, but the cost of extensive gloss annotations as well as collecting sign videos with skilled signers present significant challenges.

To tackle this issue, We make variants of development and test splits of PHOENIX-2014 [1] with our automated pipeline and name our benchmark dataset with diverse backgrounds Scene-PHOENIX.
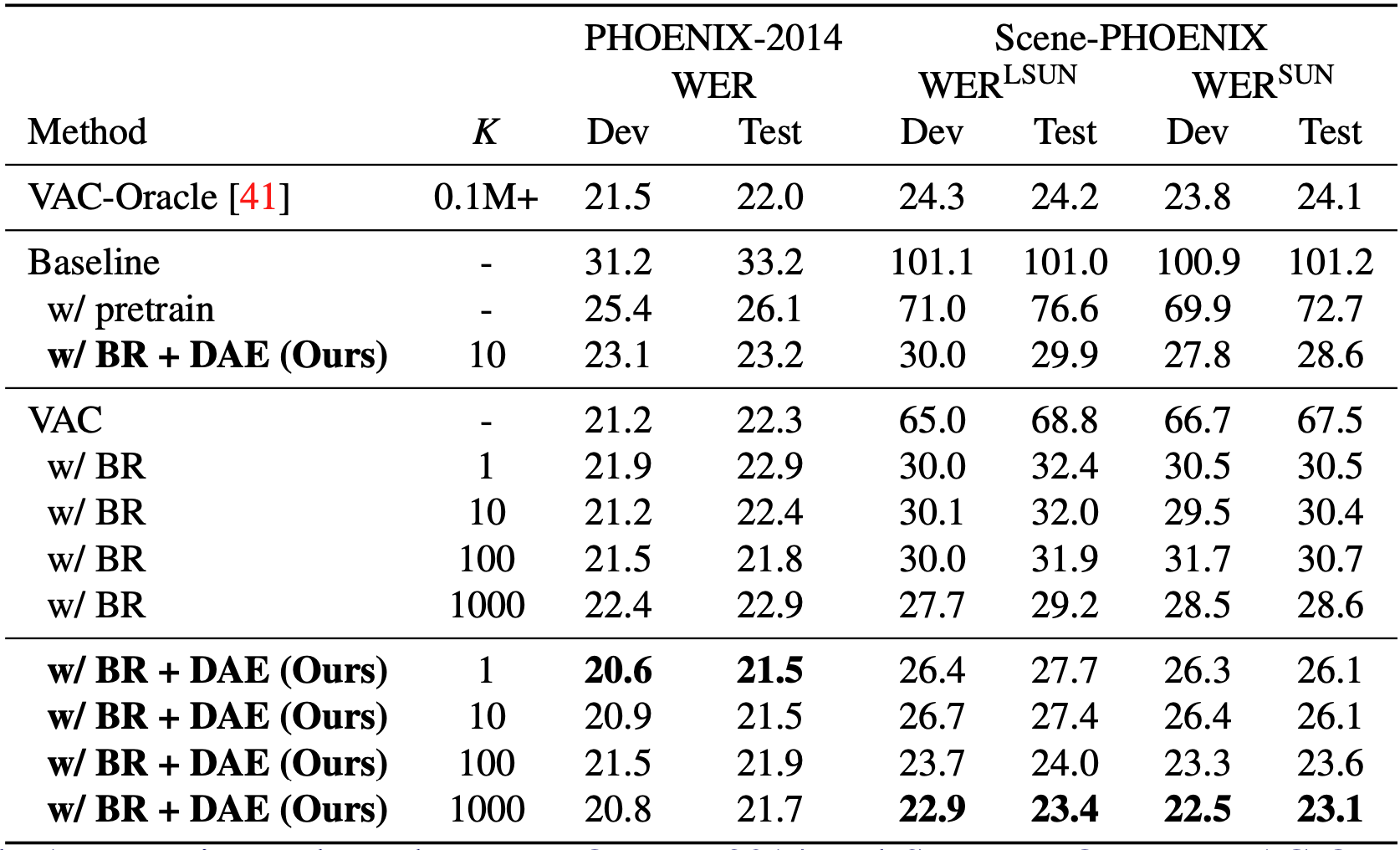
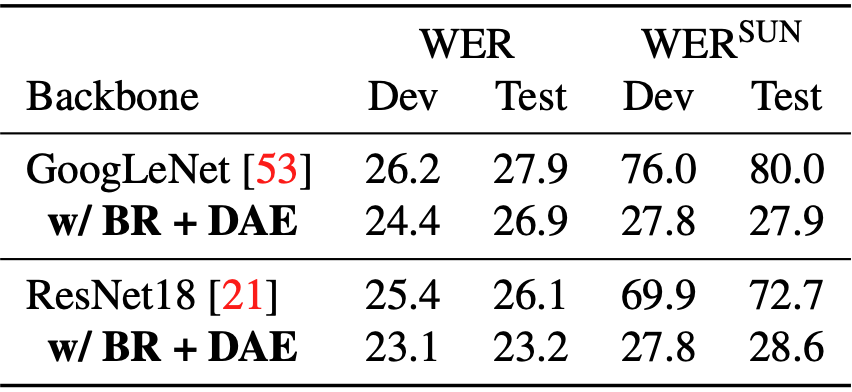
Based on our Scene-PHOENIX dataset, we find that current CSLR approaches are not robust to background shifts. Baseline (ResNet-18 [2] + 1D-CNN) and VAC [3] which is the state-of-the-art model in the CSLR field severely degrade when tested on Scene-PHOENIX.

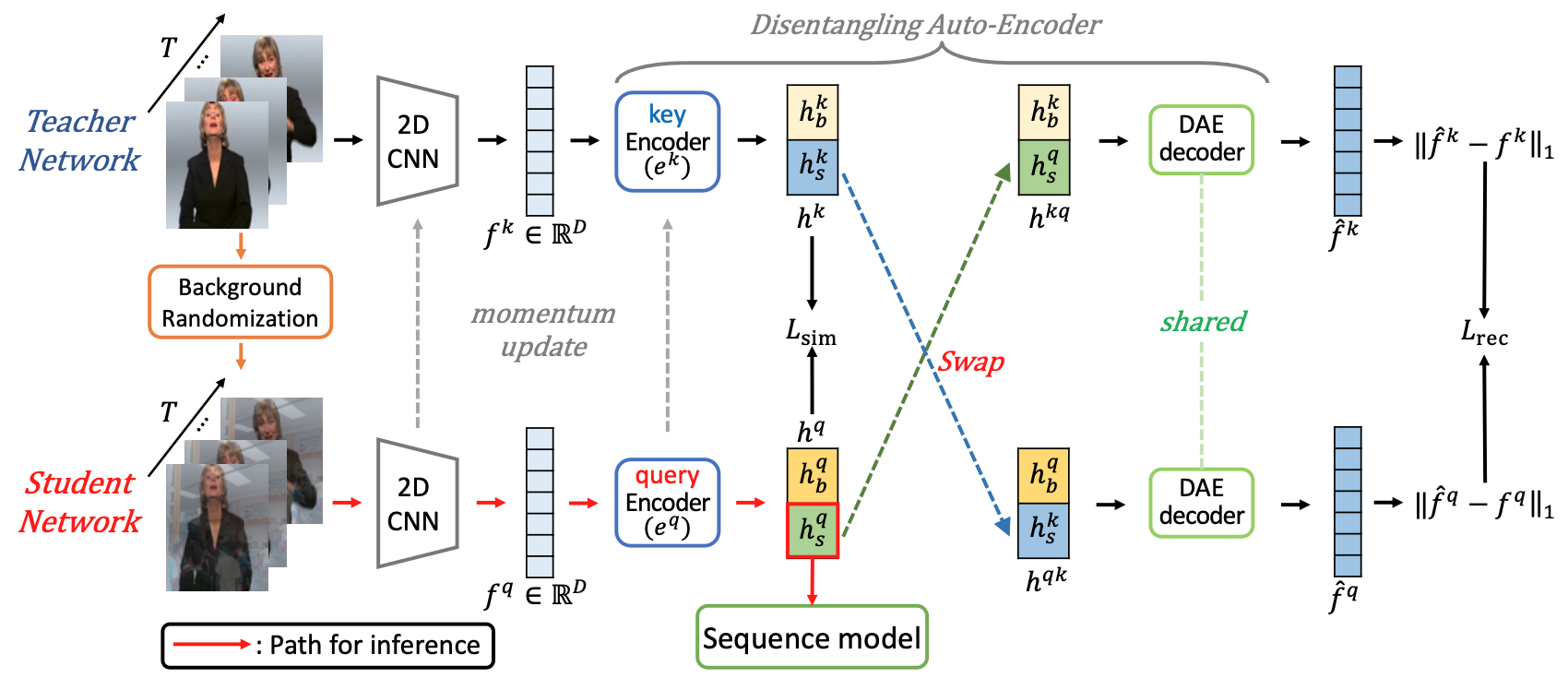
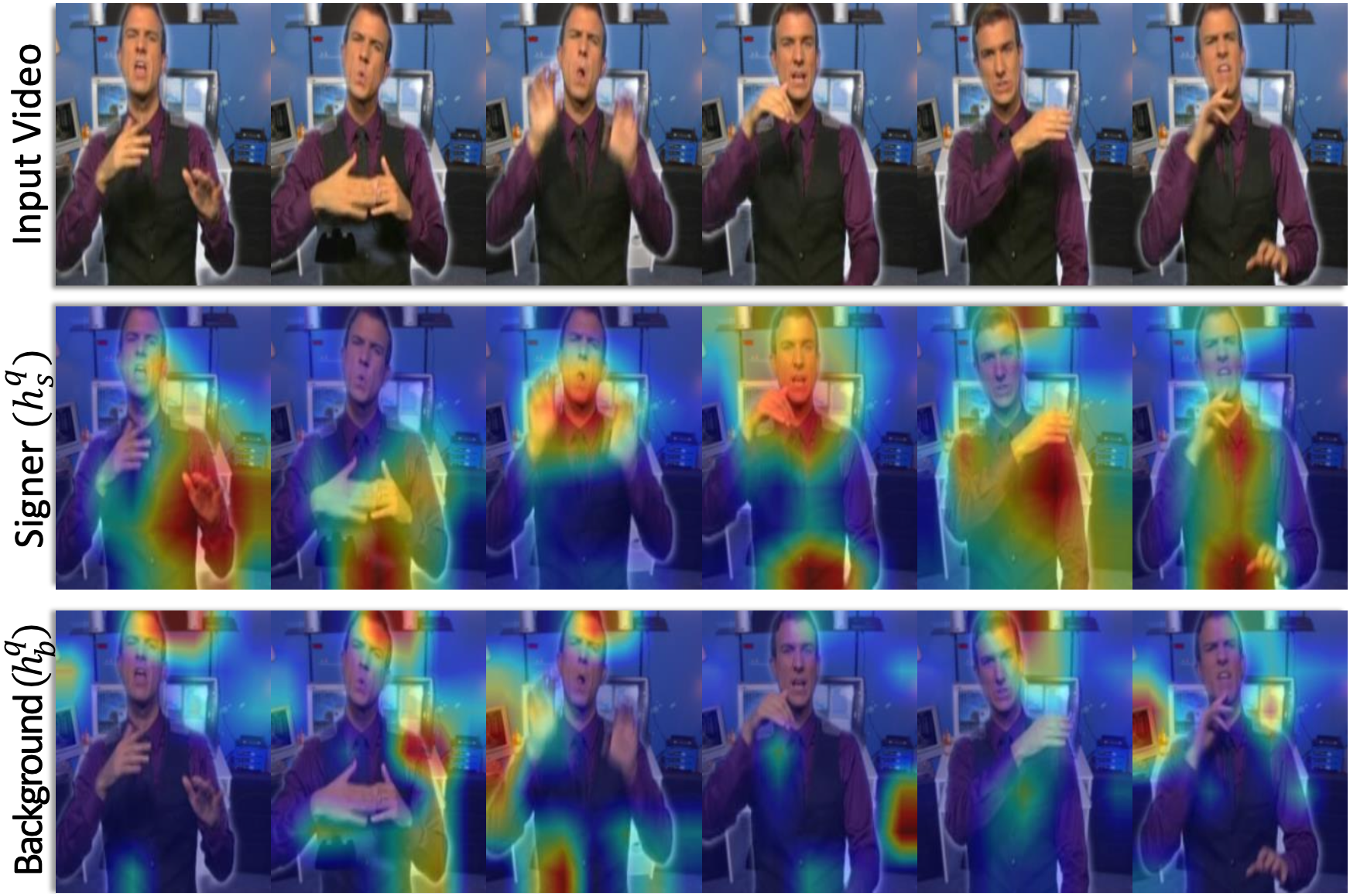
Our framework comprises of (1) Background Randomization (BR), which simply generates a sign video with new background via mixup [4] to simulate background shift, and (2) Disentangling Auto-Encoder (DAE) that aims to disentangle the signer from videos with background in latent space.


[1] Koller, Oscar, Jens Forster, and Hermann Ney. "Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers." Computer Vision and Image Understanding 141 (2015): 108-125.
[2] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[3] Min, Yuecong, et al. "Visual alignment constraint for continuous sign language recognition." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[4] Zhang, Hongyi, et al. "mixup: Beyond empirical risk minimization." arXiv preprint arXiv:1710.09412 (2017).
[5] Yu, Fisher, et al. "Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop." arXiv preprint arXiv:1506.03365 (2015).
[6] Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
If you find our work useful for your research, please cite with the following bibtex:
@inproceedings{jang2022signing,
title={Signing Outside the Studio: Benchmarking Background Robustness for Continuous Sign Language Recognition},
author={Jang, Youngjoon and Oh, Youngtaek and Cho, Jae Won and Kim, Dong-Jin and Chung, Joon Son and Kweon, In So},
booktitle={British Machine Vision Conference (BMVC)},
year={2022}
}