Additional Experiments
We show more experimental results to support our framework's novelty.
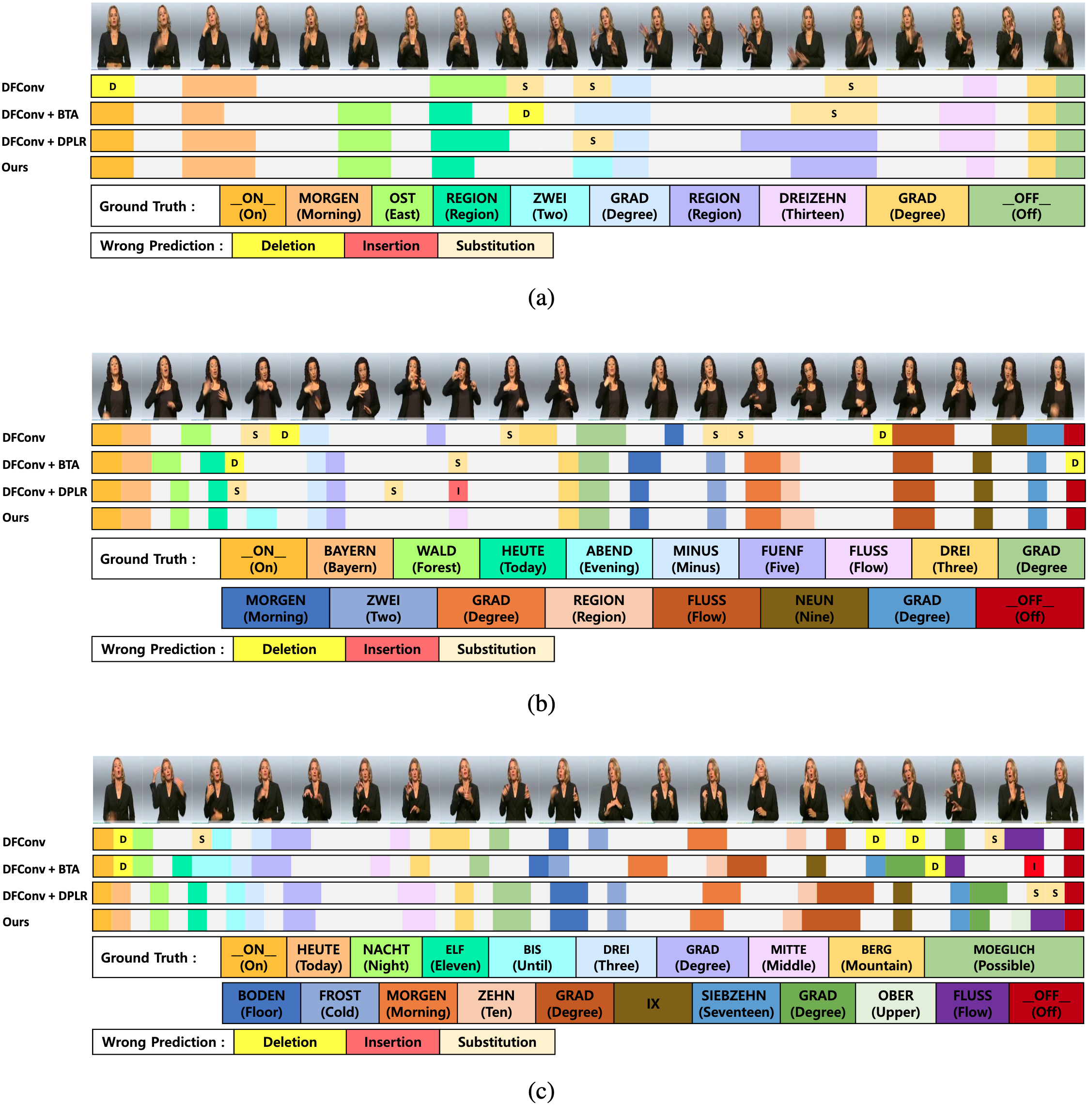
Robustness Comparison
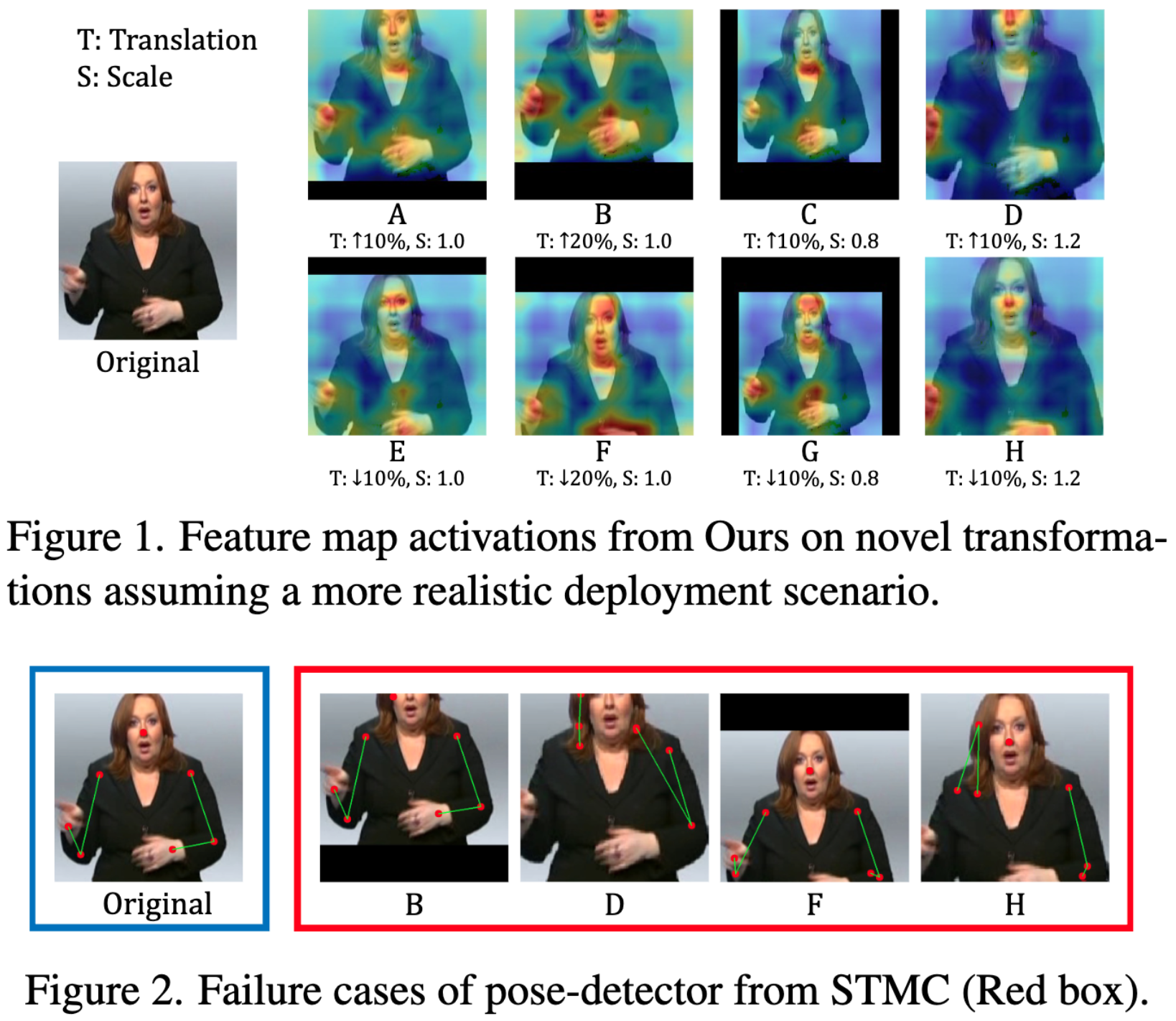
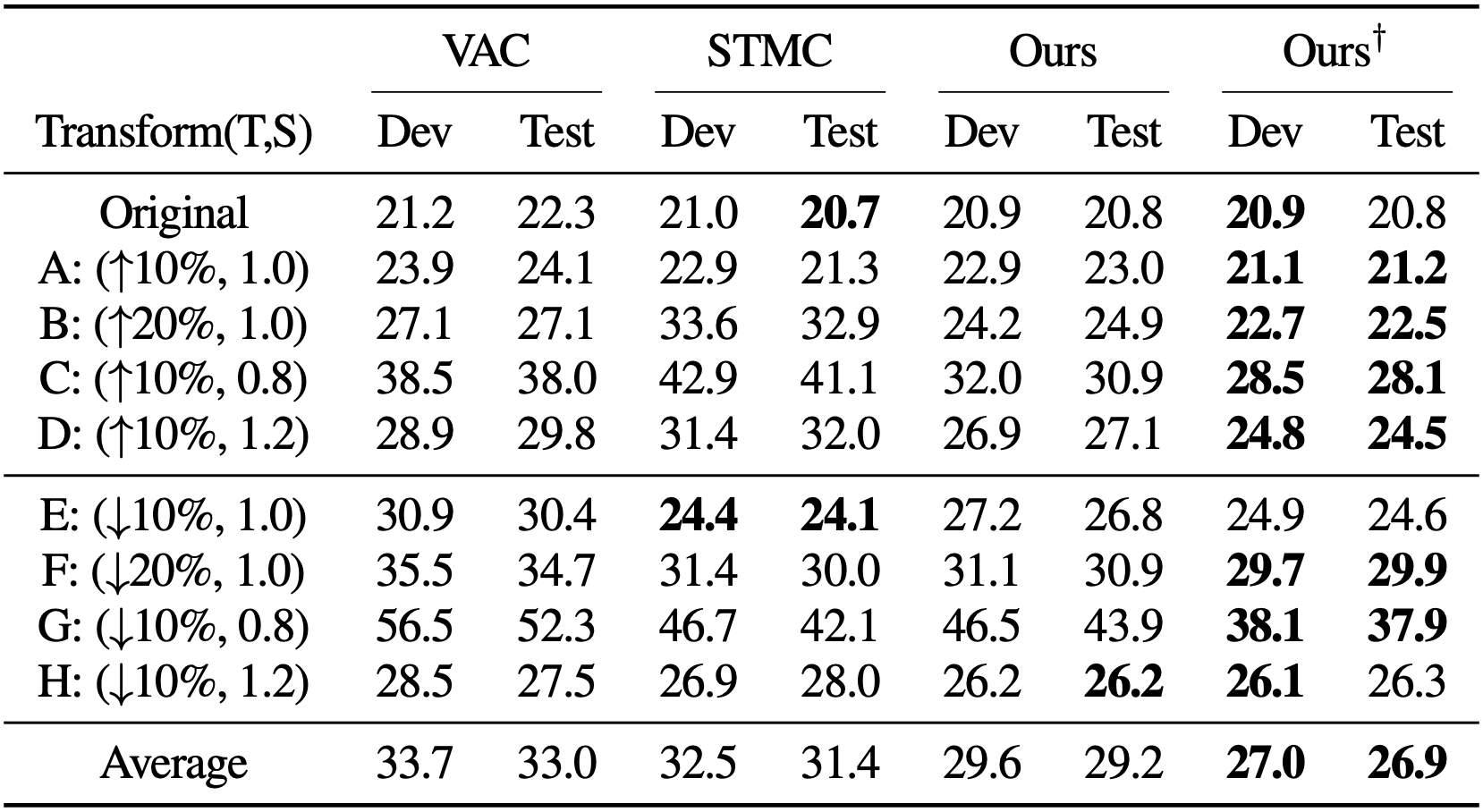
We show our framework's the robustness in a real world scenario by chainging scale and translation during the inference time. Futhermore, we show the failure cases of pose-detector in STMC [1], where the transformation (scale, translation) are adapted. Note that our framework requires only RGB modality.
Efficiency Analysis
We compare the computational complexity with the most recent multi-cue based method, STMC. Even though the pose detector of STMC is light-weight, it still induces the bottleneck in the inference time. We highlight that DFConv significantly reduces both FLOPs and inference time by pulling out the pose estimator. For reference, in out environment, extracting human keypoints with HRNet [2] from PHOENIX-2014 dataset [3] takes 2-3 GPU days. Note that we implement STMC due to the absence of the code.
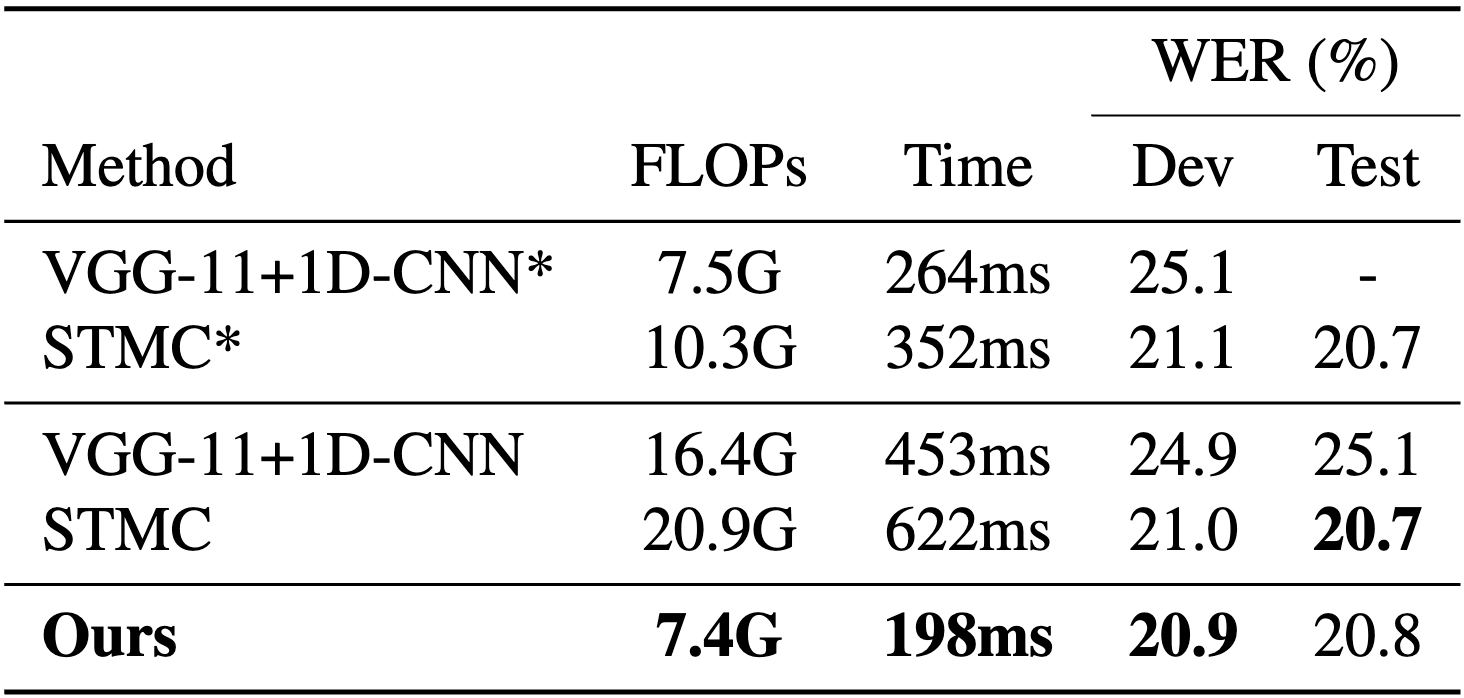
Comparison of computational cost and inference time with STMC. (*): we directly take the reported results in the original STMC paper.
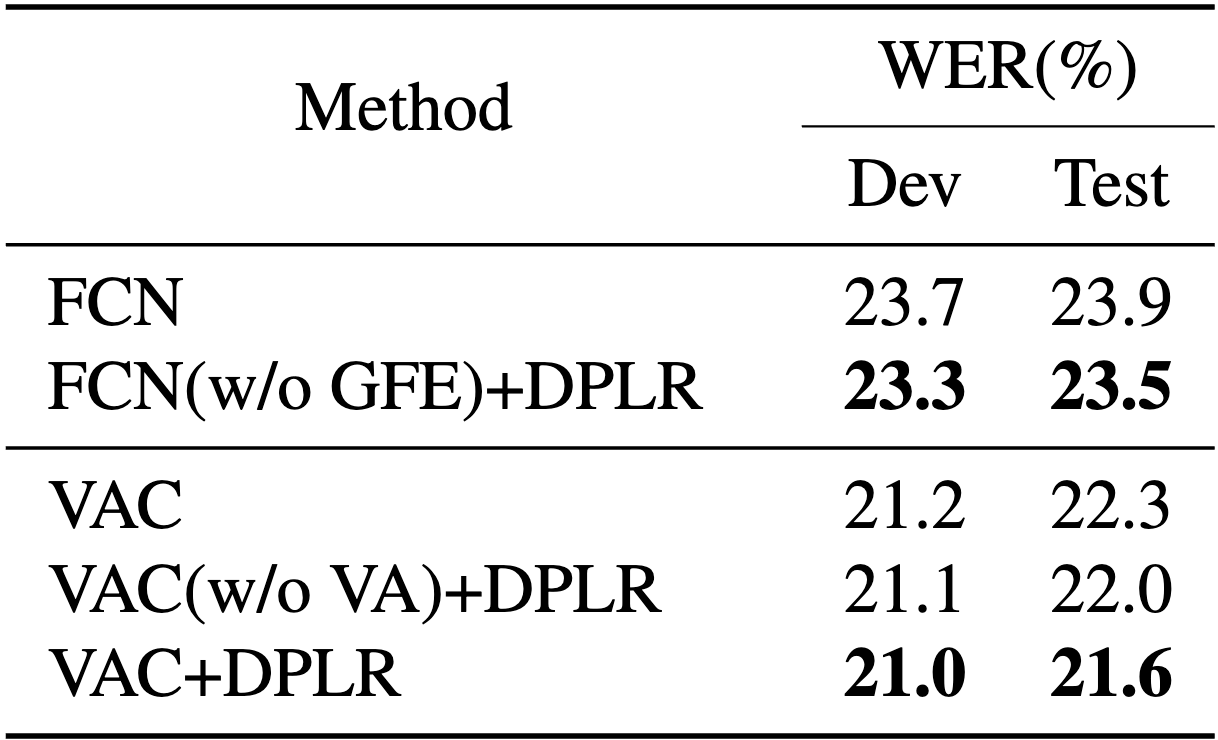
Generality of DPLR
To demonstrate the wide applicability of DPLR, we compare DPLR with other CSLR approaches using pseudo-labeling.